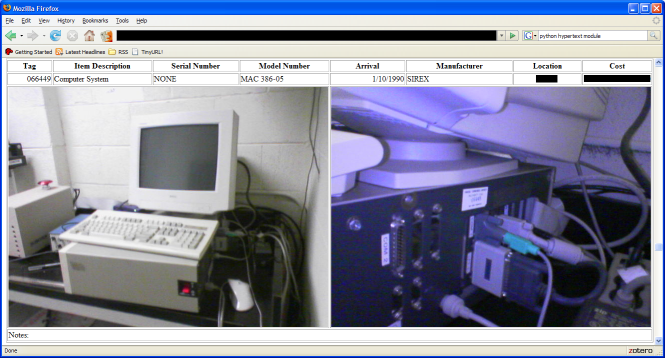
One good thing about the switch from the legacy administrative computing system to the new Banner setup is now I can more easily get an unformatted table of my department’s equipment inventory instead of a printed report. This matters to me for a few reasons:
- The default inventory reports always come out sorted by inventory tag. I have no idea why. If you have anything more than a handful of items to inventory, you would sort them by room, just like you’d identify them when walking around. Since I have somewhere around 100 items to inventory across 6-7 buildings, it’s a pain and rather error-prone to manually mark the ones in a particular building.
- Even when I got a report sorted by location, that doesn’t help a great deal with items that I only see during inventory time, or during a random audit. My memory just isn’t that good, and occasionally an item will move from one room to another without my knowledge. Photos of the items would help greatly in finding them, but the default reports don’t include any.
So this year, within a few hours of first asking for it, I got a nice CSV file of our inventory from the Business Office (thanks, Matt). It included lines like
74396,"Fork Lift, Electric",SU 803647,F30,CATERPILLAR,5/1/2001,CH106,13900,Center for Manufacturing Research,6700
that I could work with. I had text files from previous years on the old system, but they were much weirder to parse. This opened right up in Excel without issue, so I had hope for a much cleaner implementation of my old Python inventory scripts.
Man, I love Python. There’s a built-in CSV module that parses lines into lists, and separates values on each line into separate items in those lists. No parsing required on my part. There’s a nice third-party module for generating HTML markup (original site is down, but see this link from archive.org for the module). And it’s a mature enough language to where a years-old Usenet post on sorting is still useful.
On a procedural rather than technical front, I started going around a couple of years ago and snapping pictures of items as I inventoried them. The old camera-phone pictures aren’t great, but they’re good enough to identify an item and find its property tag. So now I had a table of inventory data, and a big folder of JPGs named according to the item’s property tag. So now to convert them into useful web pages:
import csv
import os
import string
from HyperText.XHTML import TABLE, TR, TH, TD, IMG, DIV, HEAD, STYLE, BR
from HyperText.Documents import Document
notesDict = {
'064286':'(2007) Surplused',
}
"""A set of comparer classes."""
## http://groups.google.com/group/comp.lang.python/msg/42b5a84450278ab2
class CmpComposite:
"""Takes a list of compare functions and sorts in that order."""
def __init__(self,*comparers):
self.comparers=comparers
def __call__(self,a,b):
for cmp in self.comparers:
c=cmp(a,b)
if c:
return c
return 0
class CmpInverse:
"""Inverses the effect of a cmp."""
def __init__(self,cmp):
self.cmp=cmp
def __call__(self,a,b):
return -self.cmp(a,b)
class CmpColumn:
"""Sorts on an index of a sequence."""
def __init__(self,column):
self.column=column
def __call__(self,a,b):
return cmp(a[self.column],b[self.column])
class CmpAttr:
"""Sorts on an attribute."""
def __init__(self, attr):
self.attr = attr
def __call__(self, x, y):
return cmp(getattr(x, self.attr), getattr(y, self.attr))
reader=csv.reader(open('inventory_control_listing_13900.csv','rb'))
equipmentList = []
for row in reader:
(tag, description, serial, model, manufacturer, arrival,
location, code, department, cost) = row
equipmentList.append((tag, description, serial, model, manufacturer,
arrival, location, cost))
for sortBy in ['tag', 'location']:
if sortBy=='tag':
equipmentList.sort(CmpColumn(0))
elif sortBy=='location':
equipmentList.sort(CmpColumn(6))
outFilename = "by-%s.html" % (sortBy)
print
print "Would print to %s" % (outFile)
print
n=0
seenTags = []
inventoryTableList=DIV()
for equipmentItem in equipmentList:
(itemTag, itemDescription, itemSerial, itemModel, itemManufacturer,
itemArrival, itemLocation, itemCost) = equipmentItem
try:
seenTags.index(itemTag)
except ValueError:
seenTags.append(itemTag)
n=n+1
if (n%2)==0:
inventoryTable=TABLE(border='1',style='page-break-after: always')
else:
inventoryTable=TABLE(border='1')
headerRow=TR()
headerRow.append(TH('Tag'))
headerRow.append(TH('Item Description'))
headerRow.append(TH('Serial Number'))
headerRow.append(TH('Model Number'))
headerRow.append(TH('Arrival'))
headerRow.append(TH('Manufacturer'))
headerRow.append(TH('Location'))
headerRow.append(TH('Cost'))
inventoryTable.append(headerRow)
itemRow=TR()
if itemTag[0] in string.digits:
itemTag=''.join(['0',itemTag])
itemRow.append(TD(itemTag,align='right'))
itemRow.append(TD(itemDescription))
itemRow.append(TD(itemSerial))
itemRow.append(TD(itemModel))
itemRow.append(TD(itemArrival,align='right'))
itemRow.append(TD(itemManufacturer))
itemRow.append(TD(itemLocation,align='center'))
itemRow.append(TD("$%.2f" % (float(itemCost)),align='right'))
inventoryTable.append(itemRow)
imageRow=TR()
if os.path.exists("%s.jpg" % itemTag):
imageRow.append(TD(IMG(src="%s.jpg" % itemTag),
colspan=4,align='center',width='640'))
else:
imageRow.append(TD(IMG(src="missing.gif"),
colspan=4,align='center',width='640'))
if os.path.exists("%s-detail.jpg" % itemTag):
imageRow.append(TD(IMG(src="%s-detail.jpg" % itemTag),
colspan=4,align='center',width='640'))
else:
imageRow.append(TD(IMG(src="missing.gif"),
colspan=4,align='center',width='640'))
inventoryTable.append(imageRow)
notesRow=TR()
if notesDict.has_key(itemTag):
notesRow.append(TD("Notes: %s" % notesDict[itemTag],colspan=8))
else:
notesRow.append(TD("Notes:",colspan=8))
inventoryTable.append(notesRow)
inventoryTableList.append(inventoryTable)
inventoryTableList.append(BR())
head=HEAD()
head.append(STYLE(type='text/css'))
htmlOutput=Document(head,inventoryTableList)
htmlFile=open(outFilename,'w+')
htmlOutput.writeto(htmlFile)
htmlFile.close()
Once this script has run, I have two web pages of the same inventory data: one sorted by location, and another by property tag. I generally only use the location-sorted one, though. The CSS tries to force page breaks every two items, and judicious use of landscape printing and a bit of scaling in Firefox means I can carry around 40 pages of my report and find everything I need pretty quickly.