
by Olivia Howell
In archival work, creating descriptions and subjects for digitized archives is a time-consuming task. With the rise of new types of software and applications, using a machine to process written language has become more accessible and there are several free options. Voyant is a free web-based application that allows users to insert a text and analyze it using several different built-in tools. I explored this tool while asking the question, “could using Voyant make creating descriptions and subjects for text-based digitized archives easier?”
To answer this question and test the tool, I scanned, edited, and performed optical character recognition (OCR) on the 1929 to 1930 editions of The Oracle, Tennessee Tech’s student newspaper. OCR is a process by which a computer takes an image of text and recognizes it as textual characters instead of an image, making it readable on a computer. I then submitted the six editions of the Fall 1929 Oracle as a single text document, otherwise known as a corpus, into Voyant (example A). Voyant can recognize the separation between the different editions of The Oracle, but all the editions can also be analyzed together.
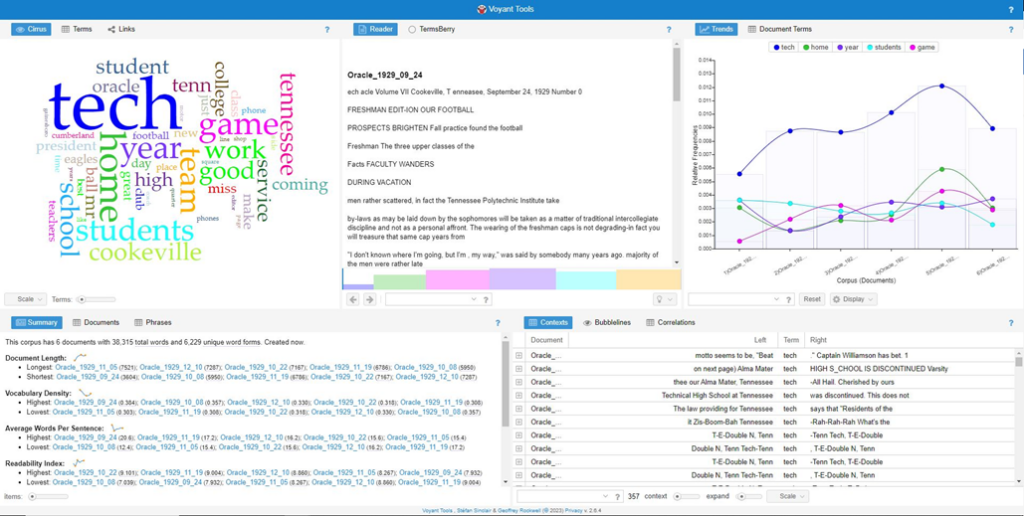
Voyant automatically blacklists common words in every corpus to help users analyze only relevant words when analyzing a document. After some exploration, I found other words specific to The Oracle that were skewing Voyant’s findings. Each edition of these Oracles had the same ads and same page headings, inflating the word count of certain words and distorting the visual interpretations created by the software, such as word clouds and word correlations. To combat this, I created a blacklist of Tennessee Tech-specific words in addition to Voyant’s. For example, “Gainesboro” continuously appeared in word clouds, making it appear as a potential subject. However, in its context, the word “Gainesboro” only appeared in ads as part of a phone number listing. Although time-consuming, once I created the blacklist of words, I could reuse them.
To compare Voyant to a human-generated description, I listed possible subjects describing each Oracle edition. When compared to the words found in the text analysis in Voyant, I found the tools most comparable to a manual description in the software were the Distinctive Words tool (Example B), Cirrus tool (Example C), and TermsBerry tool (Example D).

The Distinctive Words tool allows users to see the most unique words in each ‘section’ of the corpus (The Oracle editions) and how frequently the words are used. For example, in the September 24 edition, checking context by clicking on the specific word showed that two of the most distinct words, vacation and discontinued, corresponded to two, faculty and high school, out of the three subjects. The September 24 edition had articles about the various vacation destinations and the announcement of the high school at Tennessee Tech being discontinued. Voyant was unable to provide any viable subject heading connections in the November 5 edition.

The cirrus tool shows which words are the most frequent across the entire corpus, not per ‘section.’ I found that the Cirrus function was useful for finding subject headings that were not unique to a single edition but to The Oracle as a whole. Although it did not show up in the Distinctive Words tool, “football” showed up in the Cirrus word tool and was a common subject heading found in each edition of The Oracle. Some words, like “club,” “teachers,” “home,” and “coming,” occur frequently, but are not necessarily in every edition.

The TermsBerry function is similar to the Cirrus tool except it shows associations between words. When hovering over a word in the cluster, Voyant highlights the words that are correlated with each other. Sometimes these correlations are compound words that Voyant treats like separate words. For example, in the Cirrus tool “home” and “coming” were shown as separate, but the TermsBerry function highlights “coming” when hovering over “home” and vice versa, connecting the two words and creating a better meaning.
Overall, I found Voyant useful for finding subject terms for our use. Since each edition of The Oracle covered multiple pages with several different topics, finding the subject headings with Voyant was faster than finding subjects by hand. Voyant found many of the same subjects that were on the list generated by hand. Some shortcomings of the tool may be that for other collections, such as personal papers (correspondence and diaries), Voyant may be less useful because of the wider variety of subject matter. Also, creating a blacklist of words may take nearly as much time as finding subjects by hand.
While researching this article, I had guidance from Jenny Huffman, Archives Assistant for the Tech Archives. Research for this project coincided with class work from the Spring 2023 Archive Management and Research course taught by University Archivist Megan Atkinson.