Hidden Markov Model Based Q-Learning for Partially Observable Markov Decision Process with Discounted Rewards
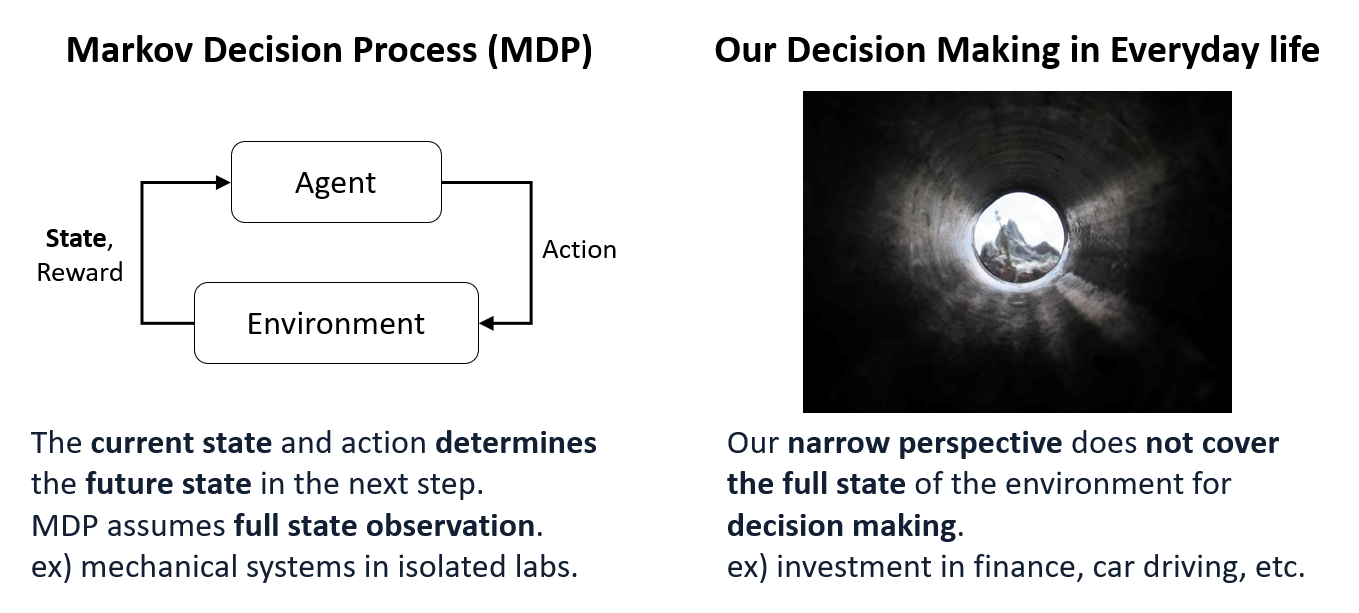
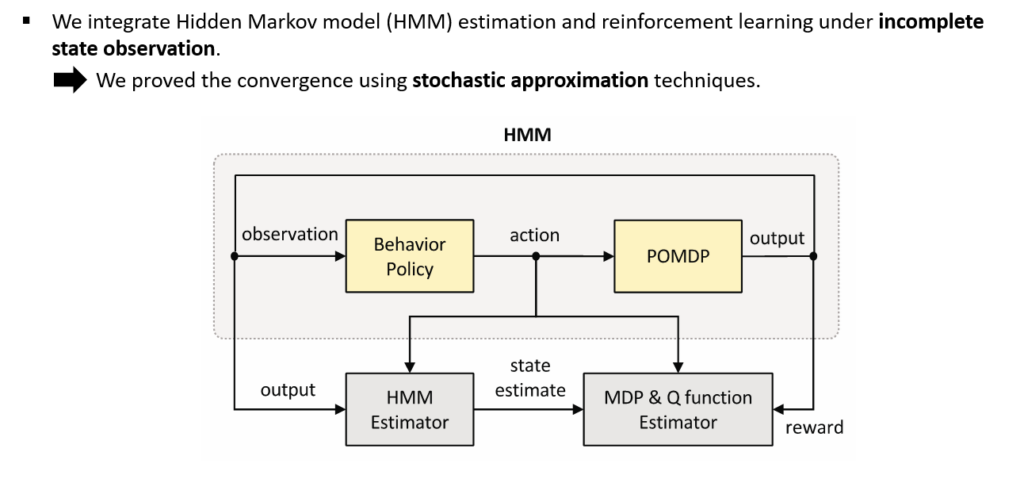
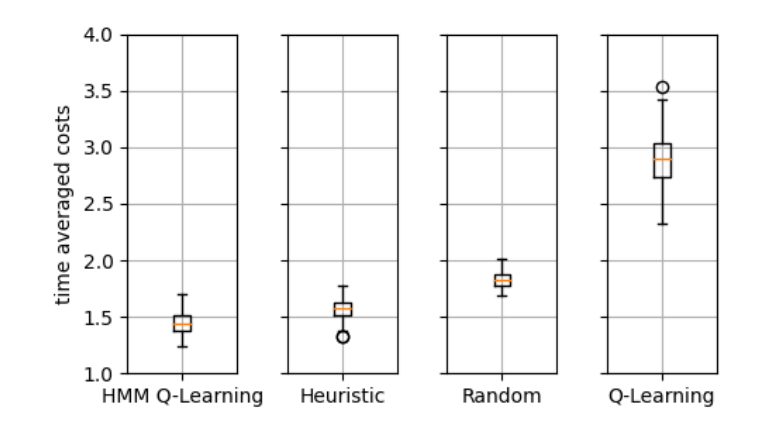
Decision-making problems in real-world are often partially observable, and dynamic models of the environments are typically unknown. Therefore, there are demands for learning methods to estimate both the dynamic models and the decision policy, given streams of rewards and incomplete state observations. This work presents an online estimation algorithm that simultaneously estimates the model parameter and belief-state-action-value function that uses discretized belief state space. Furthermore, we establish asymptotic convergence analysis for the above estimation. Also, we show that the discretized action-value function converges to the actual action-value function as we increase the number of grids for the discretization. In addition, we provide a numerical example where the introduced estimation methods show improved performance compared to the application of standard Q-learning that does not consider incomplete state observations. While this work focuses on analysis on finite observation and action space, we consider this as a step towards the theoretical understanding of the existing deep reinforcement learning methods that estimate both models and policies given incomplete observations.
BACKGROUND
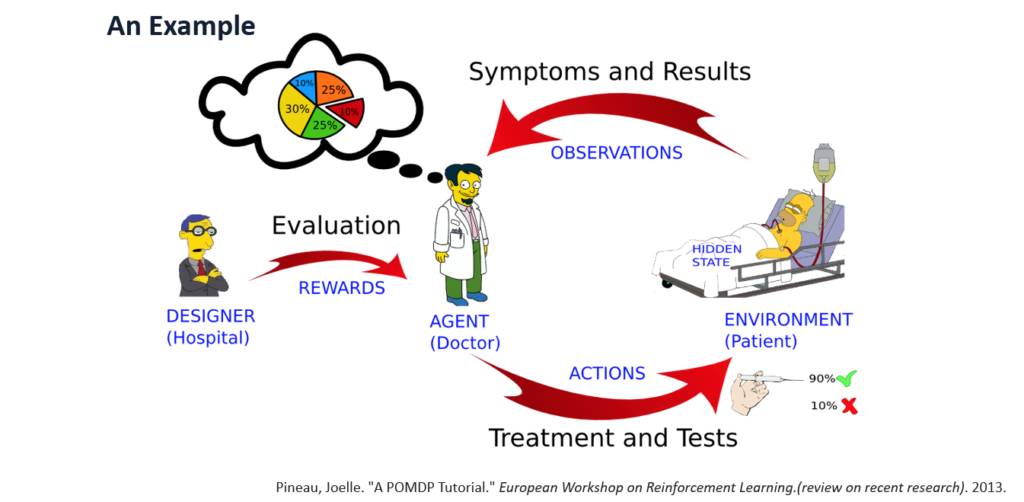
POMDP EXAMPLE
HMM BASED RL FOR POMDP

PERFORMANCE OF THE POLICY TO MACHINE REPAIR PROBLEM
Relevant Paper:
- Yoon, Hyung-Jin, Donghwan Lee, and Naira Hovakimyan. “Hidden Markov model estimation-based q-learning for partially observable Markov decision process.” 2019 American Control Conference (ACC). IEEE, 2019.